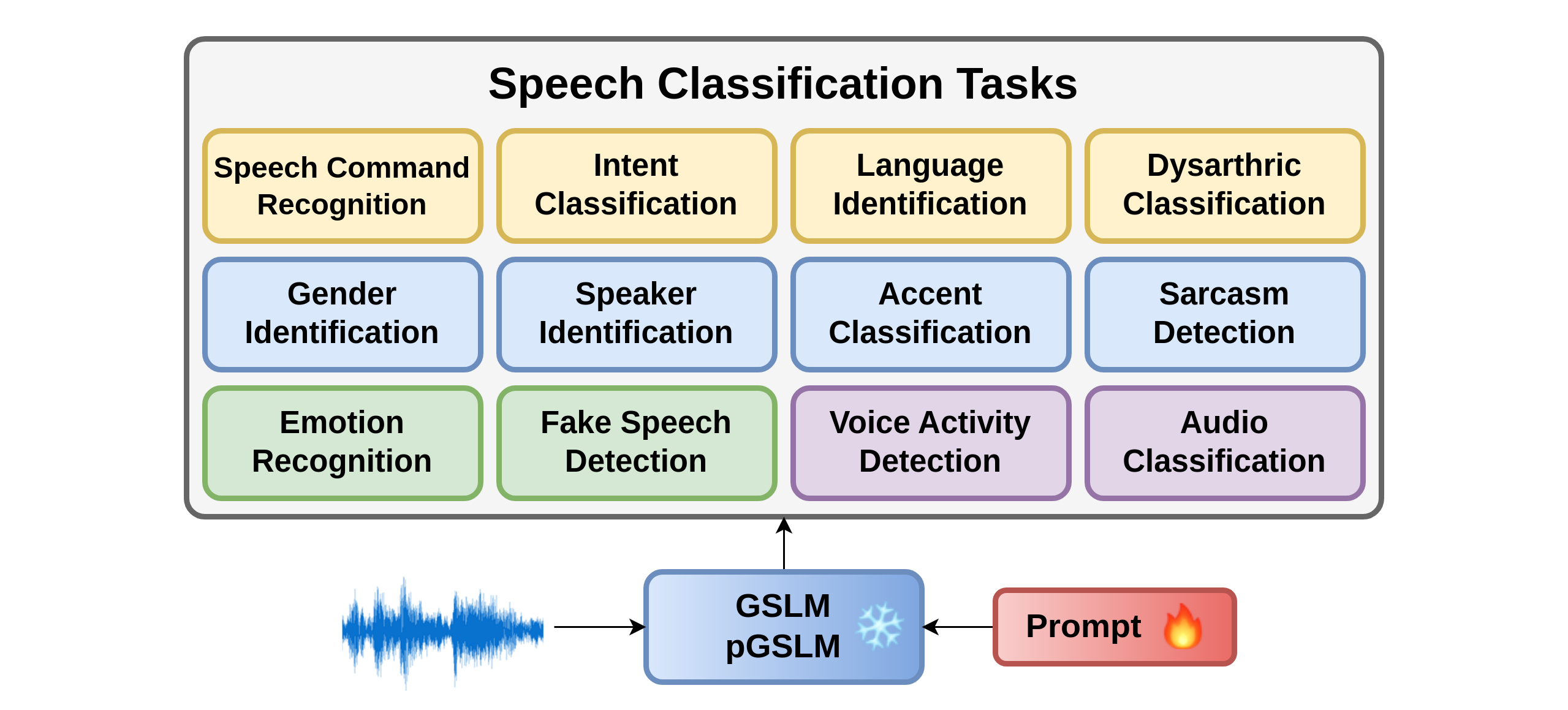
Tasks
Speech Command Recognition (SCR)
The task is to recognize which keyword is presented in a given utterance. We adopted Google Speech Commands dataset and several low-resource datasets in different languages. These include Grabo Speech Commands, Lithuanian Speech Commands, Dysarthric Mandarin Speech Commands and Arabic Speech Commands.
Intent Classification (IC)
This task classifies utterances into predefined classes to determine the intent of speakers. We used the Fluent Speech Commands dataset, where each utterance has three labels: action, object, and location.
Language Identification (LID)
This task is to recognize the languages used in an utterance.We used the Voxforge Dataset consisting of six different languages for the task.
Fake Speech Detection (FSD)
This task is to distinguish real speech from synthetic speech. We used the Logical Access (LA) part of ASVspoof dataset, which contains bona fide and spoofed speech.
Emotion Recognition (ER)
This task predicts an emotion class for each utterance. The most widely used ER dataset IEMOCAP is adopted in this work.
Dysarthria Classification (DYC)
The task is to assess the Therapy Outcome Measure (TOM) of a dysarthric patient ranging from 1 to 5 corresponding to different severities of dysarthria, and 0 for control subjects. We adopted the EasyCall Dataset for the task.
Accent Classification (AcC)
This task classifies different accents of the same language.We used the AccentDB Dataset containing 4 Indian-English accents, 4 native-English and 1 metropolitan Indian-English accent.
Sarcasm Detection (SD)
The task is to detect whether an utterance contains sarcasm. We adopted 2 datasets, Mustard and Muatard++, of which the former can be said to be a subset of the latter.
Gender Identification (GID)
The task aims to distinguish the sex of the speaker. We adopted the VoxCeleb1 Dataset and obtained the label based on the provided speaker information.
Speaker Identification (SID)
This task classifies utterances into predefined classes to determine the intent of speakers. We used the Fluent Speech Commands dataset, where each utterance has three labels: action, object, and location.
Voice Activity Detection (VAD)
This task is to detect the input audio containing speech or background noise. We used Google Speech Commands v2 as speech data and Freesound dataset as background noise data.
Audio Classification (AuC)
This task classifies different environmental sounds across human and nature. We used the ESC-50 with 50 different classes for the task.
Datasets
|
Index
|
Task | Datasets | Language | N_class | N_utt. | Content | Prosody | Speaker | Audio |
|---|---|---|---|---|---|---|---|---|---|
|
1
|
SCR | Google Speech Commands | English | 12 | 72783 | ✔ | |||
|
2
|
Grabo Speech Commands | Dutch | 36 | 6007 | ✔ | ||||
|
3
|
Lithuanian Speech Commands | Lithuanian | 15 | 809 | ✔ | ||||
|
4
|
Arabic Speech Commands | Arabic | 16 | 1600 | ✔ | ||||
|
5
|
Dysarthric Mandarin Speech Commands |
Mandarin | 19 | 570 | ✔ | ✔ | |||
|
6
|
IC | Fluent Speech Commands | English | 24 | 30043 | ✔ | |||
|
7
|
LID | Voxforge |
English, Spanish, French German, Russian, Italian |
6 | 10800 | ✔ | |||
|
8
|
FSD | ASVspoof | English | 2 | 121461 | ✔ | ✔ | ||
|
9
|
ER | IEMOCAP | English | 4 | 5531 | ✔ | ✔ | ||
|
10
|
DYC | EasyCall | Italian | 6 | 21386 | ✔ | ✔ | ||
|
11
|
AcC | AccentDB | English | 9 | 17313 | ✔ | |||
|
12
|
SD | MUStARD | English | 2 | 690 | ✔ | |||
|
13
|
MUStARD++ | English | 2 | 1202 | ✔ | ||||
|
14
|
GID | VoxCeleb1 | English | 2 | 153516 | ✔ | ✔ | ||
|
15
|
SID | VoxCeleb1 | English | 1251 | 153516 | ✔ | ✔ | ||
|
16
|
VAD |
Google Speech Commands & Freesound |
English / Audio | 2 | 109617 | ✔ | |||
|
17
|
AuC | ESC-50 | Audio | 50 | 2000 | ✔ |
Benchmark
|
Index
|
Task | Datasets | Prior |
GSLM | GSLM+ | pGSLM | pGSLM+ |
|---|---|---|---|---|---|---|---|
|
1
|
SCR (↑) | Google Speech Commands | 0.986 | 0.945 | 0.946 | 0.943 | 0.947 |
|
2
|
Grabo Speech Commands | 0.989 | 0.924 | 0.927 | 0.175 | 0.196 | |
|
3
|
Lithuanian Speech Commands | 0.918 | 0.932 | 0.955 | 0.909 | 0.795 | |
|
4
|
Arabic Speech Commands | 0.989 | 0.997 | 1.000 | 0.856 | 0.926 | |
|
5
|
Dysarthric Mandarin Speech Commands |
0.935 | 0.743 | 0.825 | 0.744 | 0.231 | |
|
6
|
IC (↑) | Fluent Speech Commands | 0.997 | 0.972 | 0.973 | 0.981 | 0.982 |
|
7
|
LID (↑) | Voxforge | 0.998 | 0.909 | 0.942 | 0.818 | 0.804 |
|
8
|
FSD (↓) | ASVspoof | 0.025 | 0.185 | 0.135 | 0.131 | 0.183 |
|
9
|
ER (↑) | IEMOCAP | 0.792 | 0.421 | 0.443 | 0.499 | 0.502 |
|
10
|
DYC (↑) | EasyCall | X | 0.763 | 0.78 | 0.838 | 0.832 |
|
11
|
AcC (↑) | AccentDB | 0.995 | 0.789 | 0.834 | 0.865 | 0.871 |
|
12
|
SD (↑) | MUStARD | 0.646 | 0.551 | 0.778 | 0.744 | 0.787 |
|
13
|
MUStARD++ | 0.652 | 0.74 | 0.752 | 0.527 | 0.582 | |
|
14
|
GID (↑) | VoxCeleb1 | 0.983 | 0.862 | 0.873 | 0.916 | 0.862 |
|
15
|
SID (↑) | VoxCeleb1 | 0.948 | X | 0.009 | X | 0.003 |
|
16
|
VAD (↑) |
Google Speech Commands & Freesound |
0.988 | 0.966 | 0.969 | 0.983 | 0.981 |
|
17
|
AuC (↑) | ESC-50 | 0.97 | 0.09 | 0.375 | 0.203 | 0.27 |
Prior Works / Previous SOTAs
Here we list the prior works that are in "Fully Supervised Learning" or "Pre-train, Fine-tune" paradigm. The model parameters are also listed for reference. Note that in SpeechPrompt v2, we only train 0.128M parameters for each task. The pre-trained speech encoder, HuBERT, and the unit langauge model, contain 89M and 151M parameters respectively. While during traning, the whole spoken langauge model (speech encoder + uLM) is fixed.
SCR - Google Speech Commands V1
Learning Efficient Representations for Keyword Spotting with Triplet Loss (Vygon and Mikhaylovskiy, SPECOM 2021)
[Link]The author used a combination of triplet-loss based metric embeddings and a kNN classifier to enhance the accuracy of a CNN-based model in keyword spotting. The model, based on res15, achieved 0.986 accuracy on the Google Speech Commands Dataset v1 testing set, with 0.25M parameters.
SCR - Grabo Speech Commands
Improving end-to-end speech-to-intent classification with reptile (Tian and Gorinski, INTERSPEECH 2020)
[Link]The authors adapt the meta-learning algorithm, Reptile to train an end-to-end Spoken Language Understanding (SLU) model. Furthermore, they incorporate pre-trained ASR models to the input of SLU models, and support cross-lingual transfer learning. Their approach achieved 0.989 on the accuracy of the testing set of the Grabo Dataset. The size of the proposed model is estimated to be 1M parameters.
SCR - Lithuanian / Dysarthric Mandarin / Arabic Speech Commands
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming (Yen et al., arXiv 2021)
[Link]SpeechAdvReprogram built a speech commands recognition system using adversarial reprogramming and transfer learning approaches with an acoustic model pretrained on the Google Speech Commands Dataset. This system, having more than 0.2M parameters, achieved 0.918, 0.823, and 0.989 on the accuracy of the testing set of the Lithuanian, Dysarthric Mandarin, and Arabic Speech Commands Dataset respectively.
LID - Voxforge / FSD - ASVspoof / ER- IEMOCAP
Universal Paralinguistic Speech Representations Using Self-Supervised Conformers (Shor et al.,ICASSP 2022)
[Link]The author proposed a 608M-parameter Conformer-based model, trained fully self-supervised on YT-U, a 900k-hour dataset from YouTube. The 12th layer of the Conformer was taken as the representation, and a linear classifier was finetuned on the downstream dataset.
AcC - AccentDB
AccentDB: A Database of Non-Native English Accents to Assist Neural Speech Recognition (Ahamad et al., LREC 2020)
[Link]The author used a CNN model for accent classification and augmented the CNN network with attention mechanism. This model achieved 0.995 on the accuracy of the testing set of AccentDB. The size of the CNN network is larger than 0.5M parameters.
GID - VoxCeleb1
VoxCeleb Enrichment for Age and Gender Recognition (Hechmi et al., ASRU 2021)
[Link]The author utilized i-vector and x-vector features to identify gender, achieving F1-scores of 0.983 and 0.978 respectively using logistic regression and DNN classifier. Both extractors were trained on MFCCs for speaker recognition using the VoxCeleb1 dataset and the ASVtorch toolkit.
VAD - Google Speech Commands Dataset V2 + Freesound
MarbleNet: Deep 1D Time-Channel Separable Convolutional Neural Network for Voice Activity Detection (Jia et al., ICASSP 2021)
[Link]NVIDIA MarbleNet is trained on a mixing of Google Speech Commands Dataset V2 (speech data) and freesound (non-speech data) with data audmentation. The task is to classify whether a given audio is speech or non-speech. NVIDIA MarbleNet is an end-to-end deep residual network, having 88,000 parameters in total, for VAD. Its accuracy on the testing set is 0.998.
AuC - ESC-50
HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection (Chen et al., ICASSP 2022)
[Link]The author proposed HTS-AT, a hierarchical audio transformer with a token-semantic module for audio classification. HTS-AT adopted a swin-transformer pretrained on ImageNet as the token-semantic module. HTS-AT, having 31M parameters, achieved 0.97 on the accuracy of the testing set of ESC-50 dataset.
Verbalizer Analysis
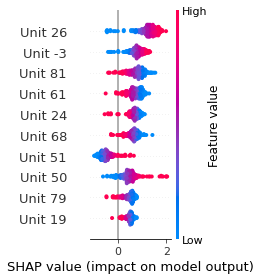
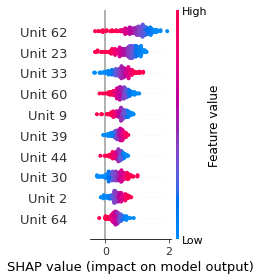
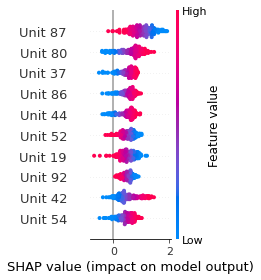
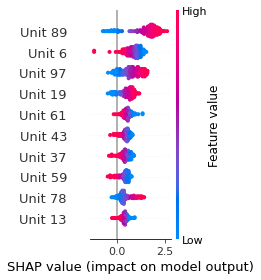
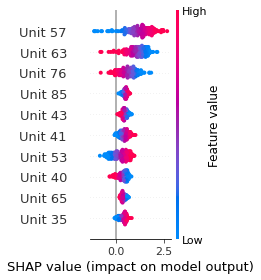
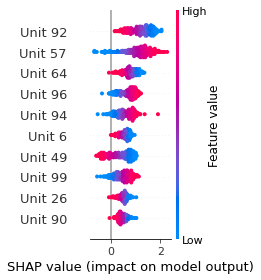
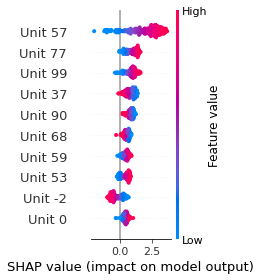
SHAP
SHAP analysis is a method to explain the output of a machine learning model. It assigns a score to each feature of the input data, based on how much the feature value is responsible for the model output. The SHAP values can be used to visualize the model output and the importance of each feature. The SHAP values are calculated using a game theory approach, where the model output is viewed as a function of the input features.
Google Speech Command Recognition
YES
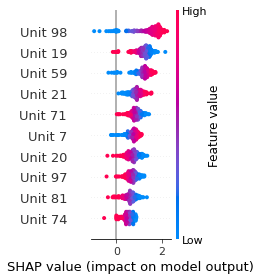
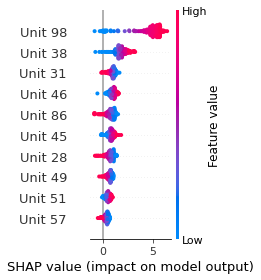
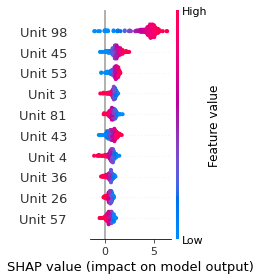
NO
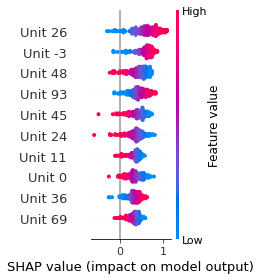
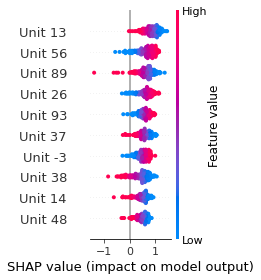
UP
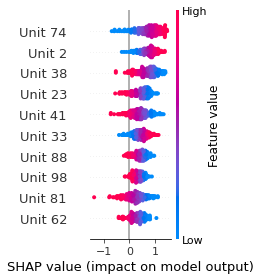
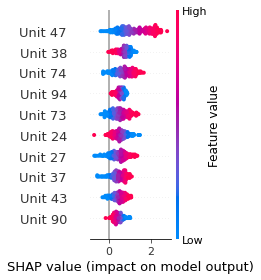
DOWN
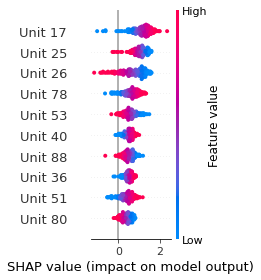
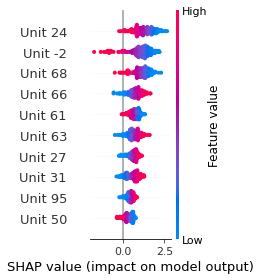
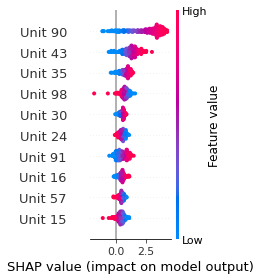
RIGHT
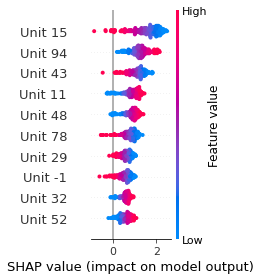
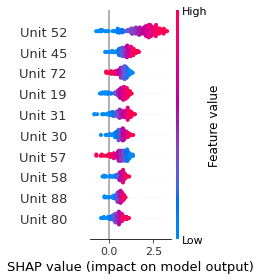
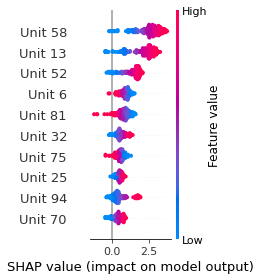
ON
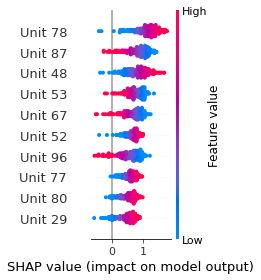
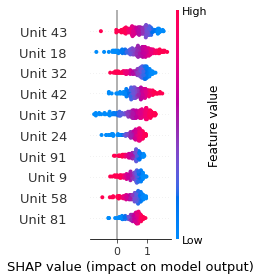
OFF
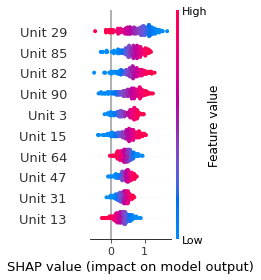
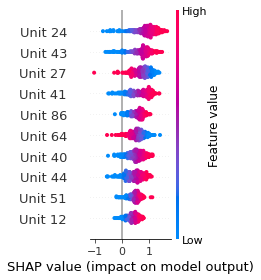
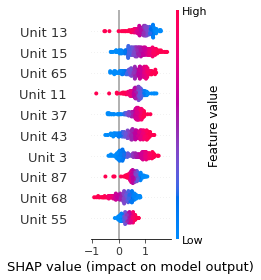
STOP
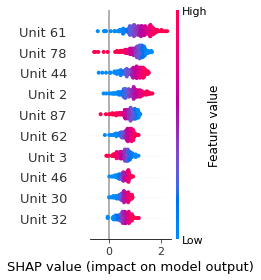
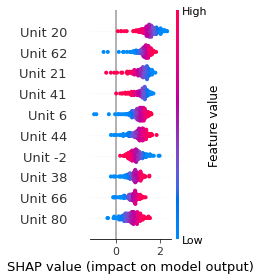
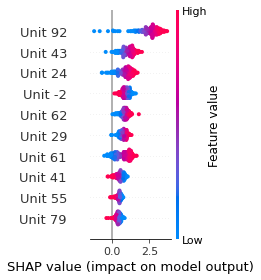
GO
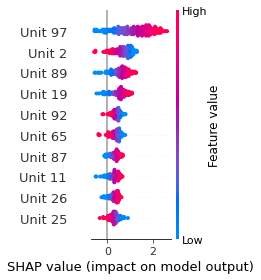
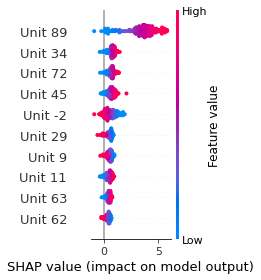
[UNKNOWN]
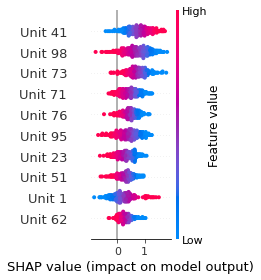
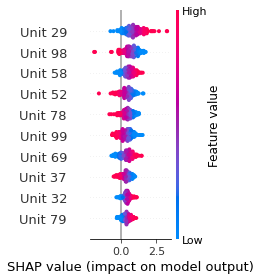
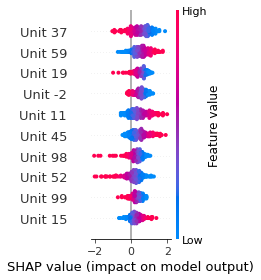
[SILENCE]
Citation
@article{chang2023speechprompt,
title={SpeechPrompt v2: Prompt Tuning for Speech Classification Tasks},
author={Chang, Kai-Wei and Wang, Yu-Kai and Shen, Hua and Kang, Iu-thing and Tseng,
Wei-Cheng and Li, Shang-Wen and Lee, Hung-yi},
journal={arXiv preprint arXiv:2303.00733},
year={2023}
}